之前已经有文章对ALBERT做了分析,谷歌全新轻量级新模型ALBERT刷新三大NLP基准!
ALBERT的改进为:
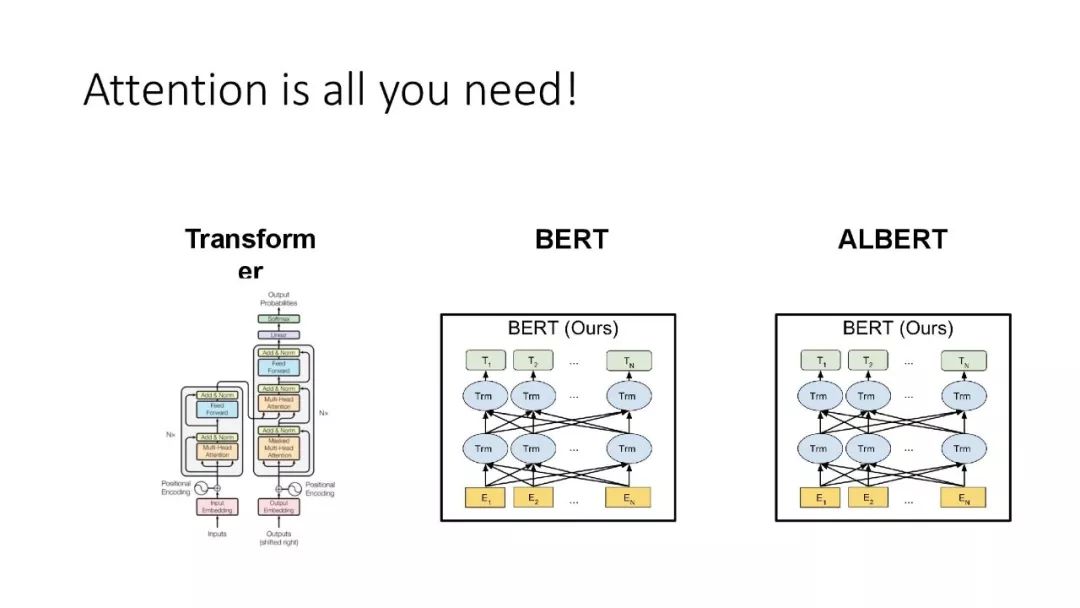
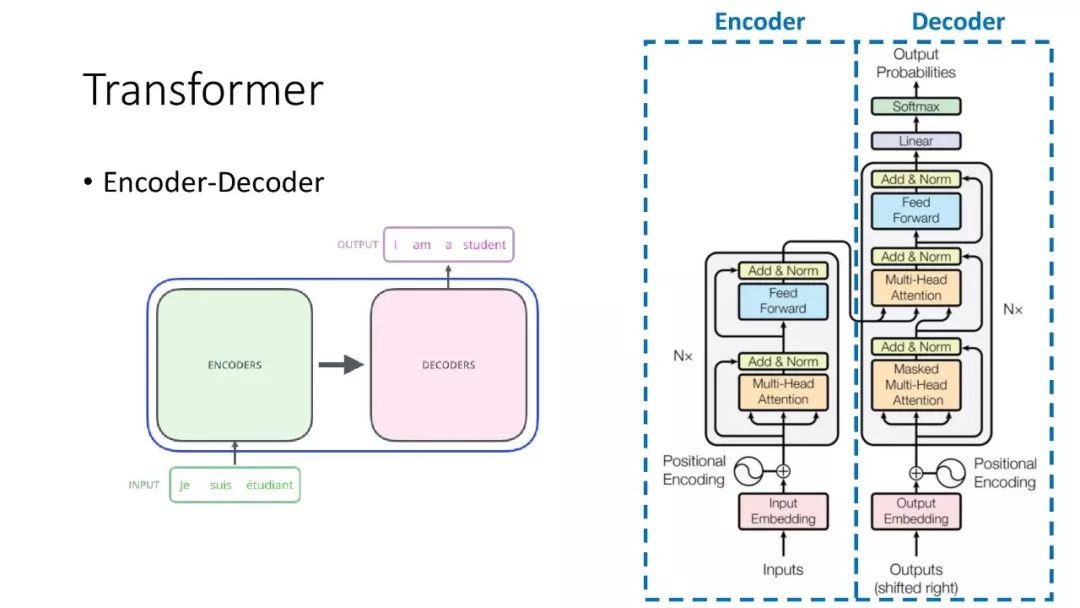
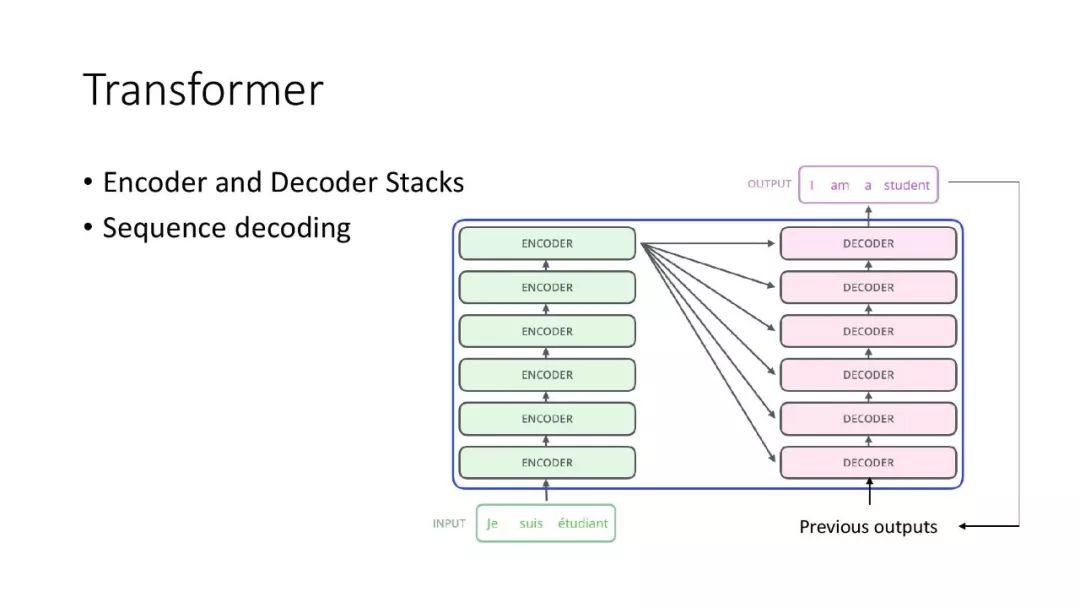
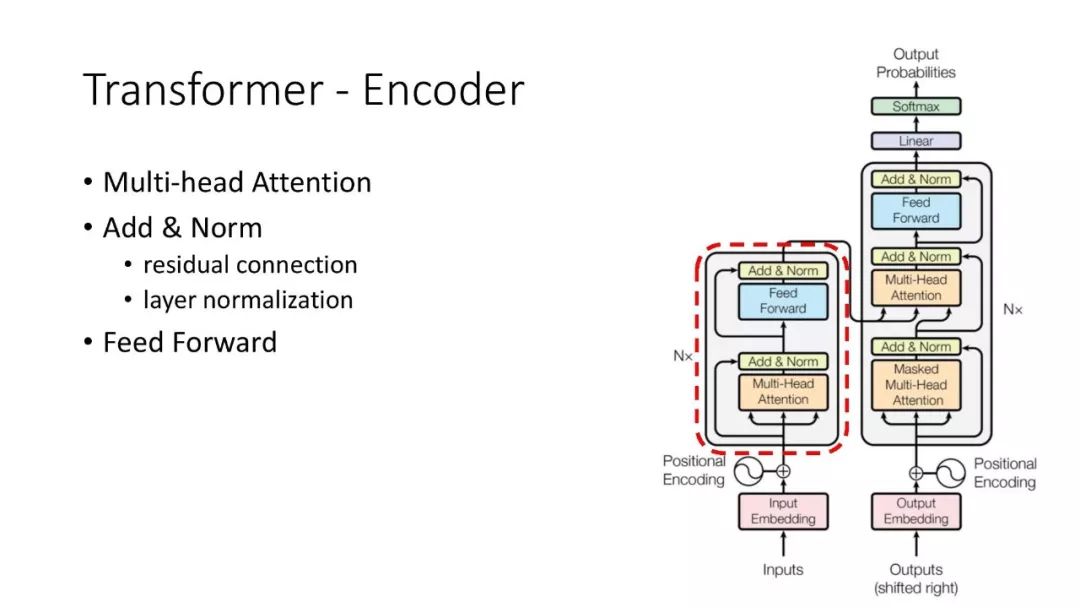
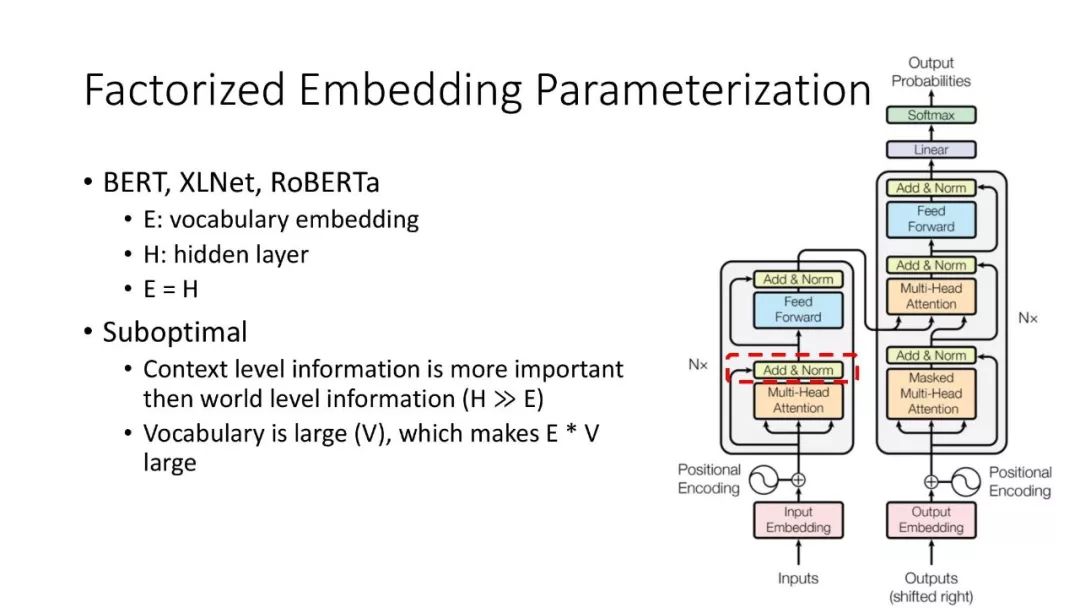
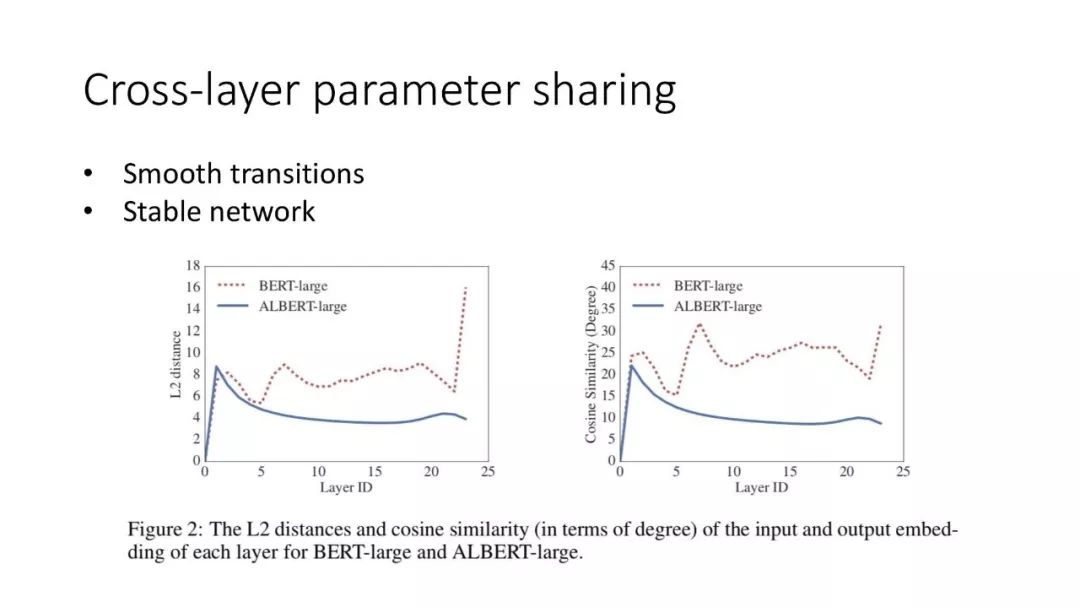
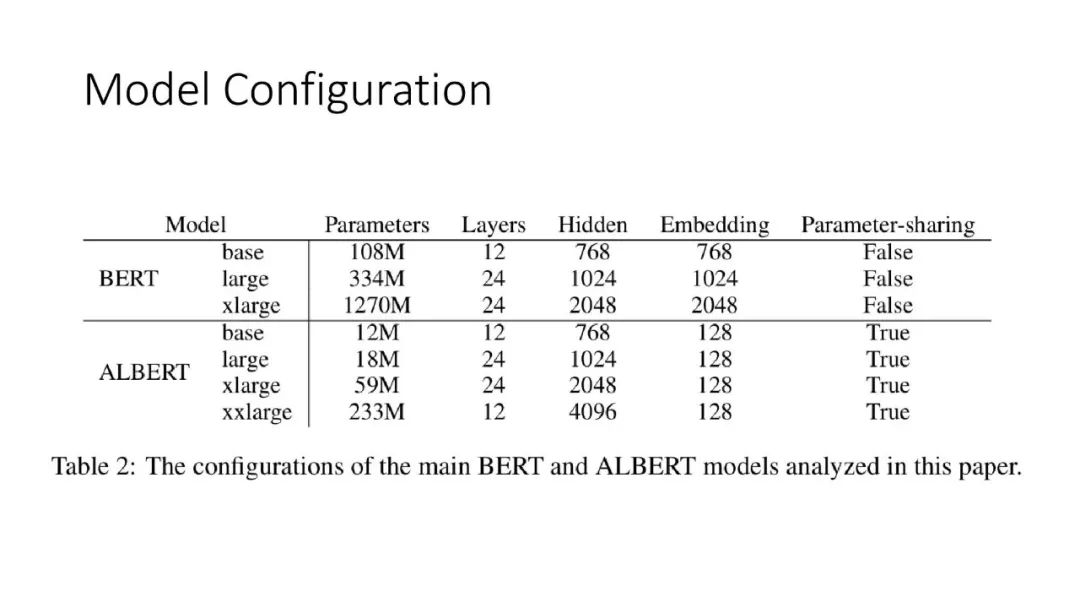
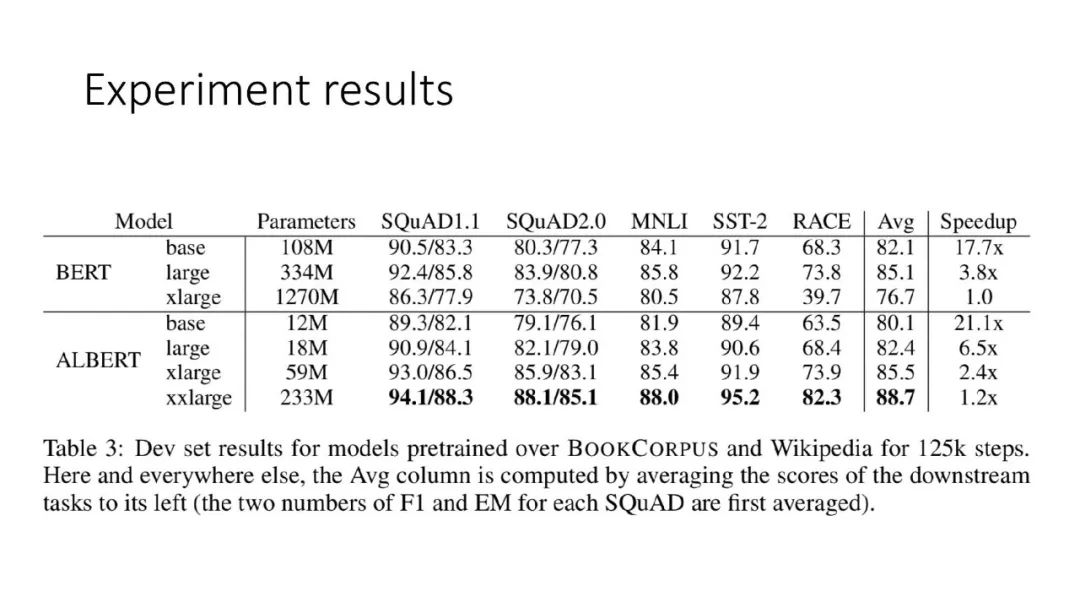
ALBERT结合了两种参数约简(parameter reduction)技术,消除了在扩展预训练模型时的主要障碍。第一个技术是对嵌入参数化进行因式分解(factorized embedding parameterization)。通过将大的词汇表嵌入矩阵分解为两个小的矩阵,将隐藏层的大小与词汇表嵌入的大小分离开来。这种分离使得在不显著增加词汇表嵌入的参数大小的情况下,更容易增加隐藏大小。第二种技术是跨层参数共享(cross-layer parameter sharing)。这种技术可以防止参数随着网络深度的增加而增加。
公众号:新智元谷歌全新轻量级新模型ALBERT刷新三大NLP基准!我们公众号也做了一个slides来帮助读者理解该论文。
Slides

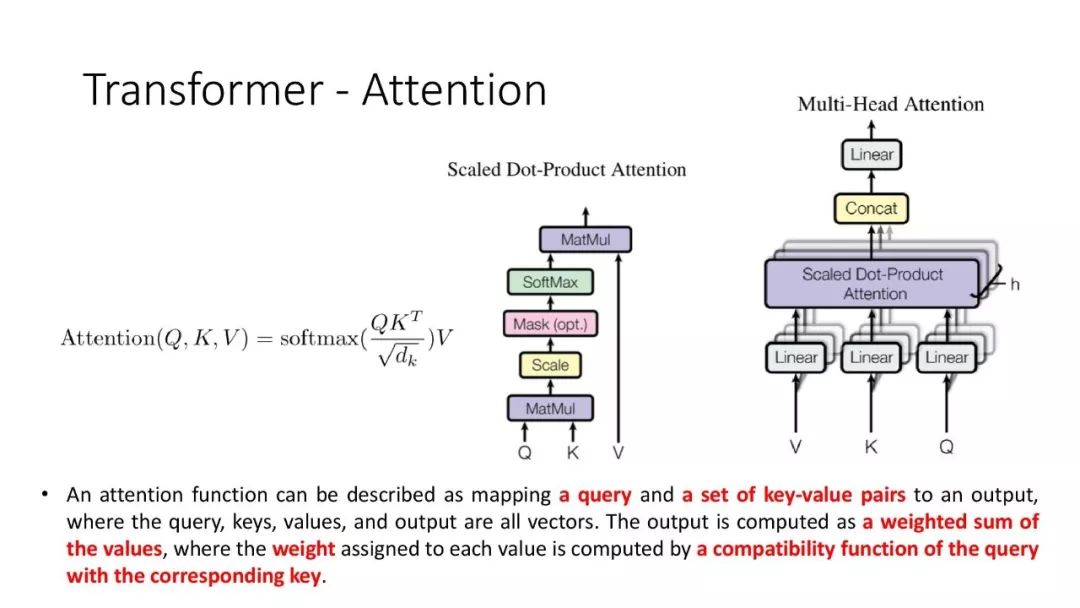

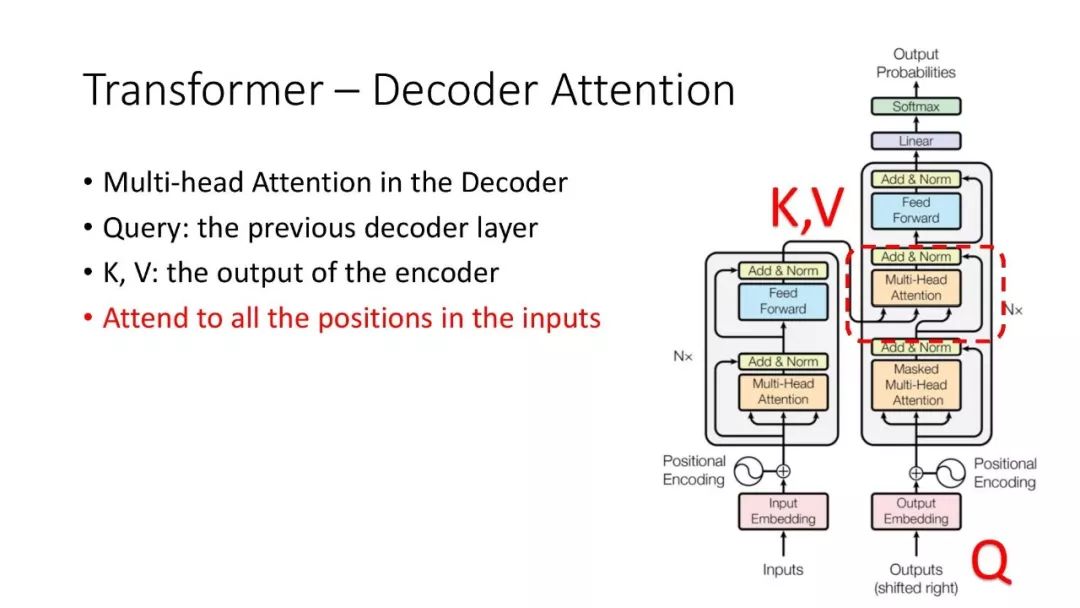

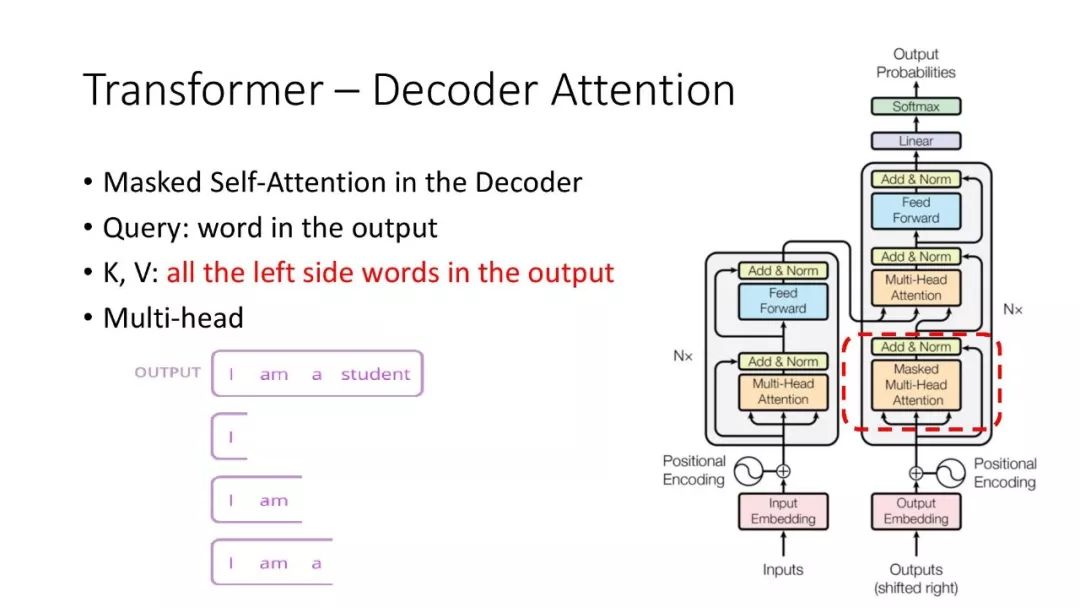

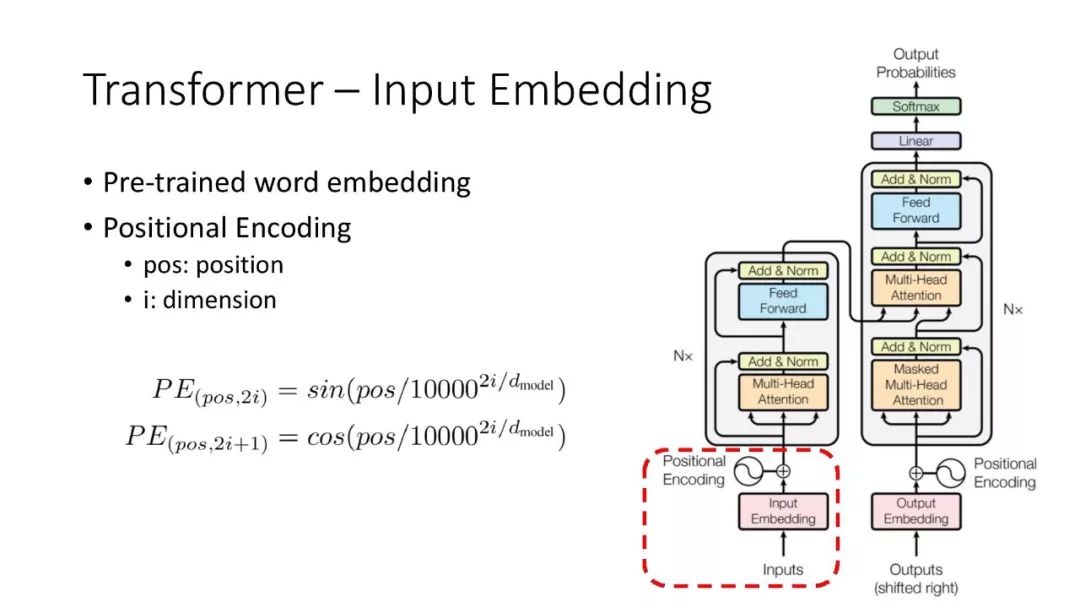
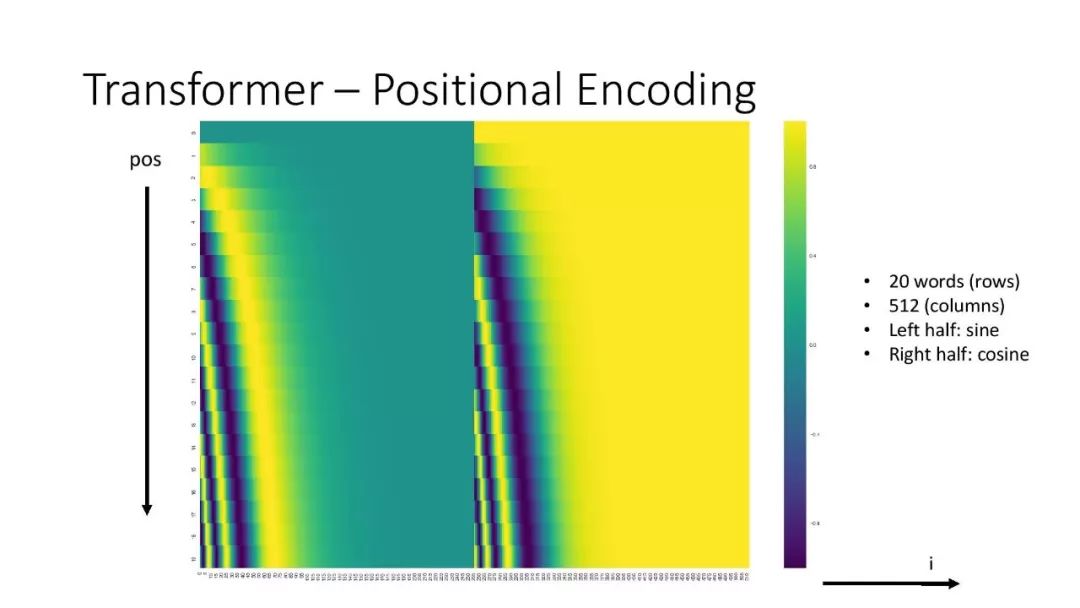



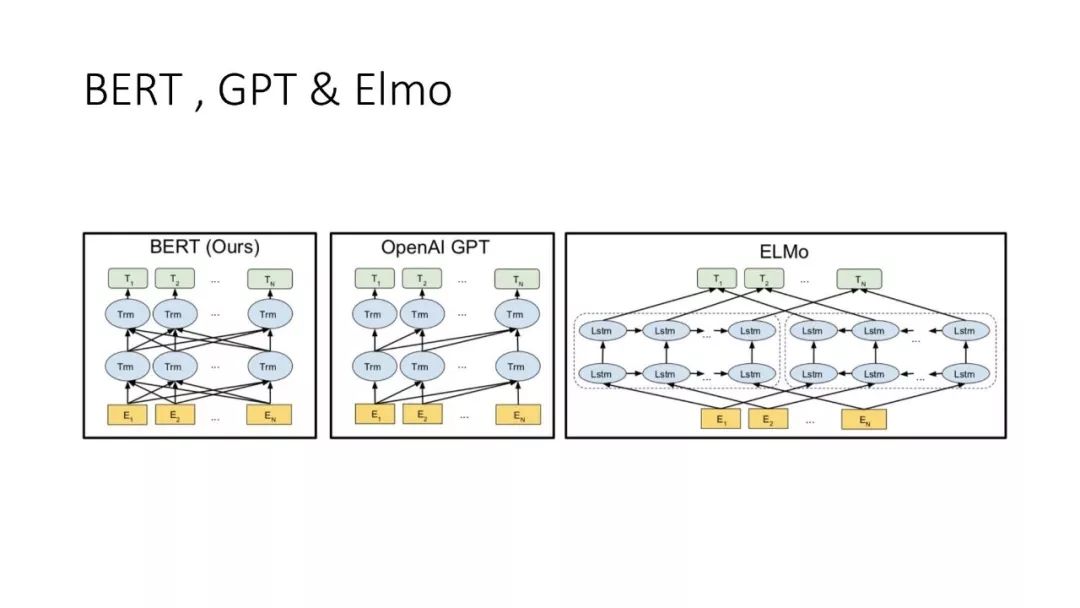



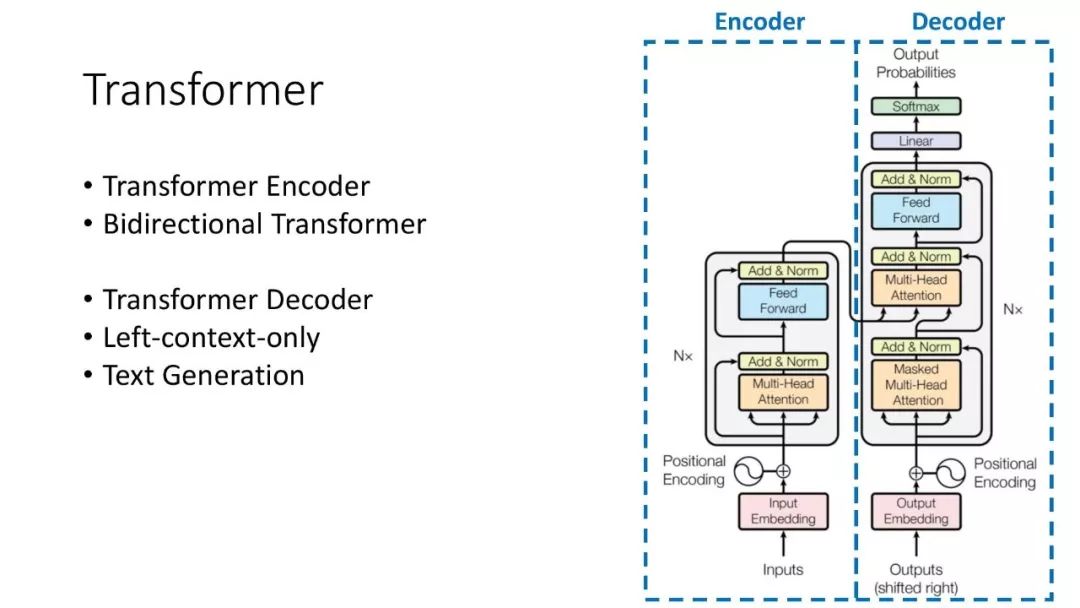
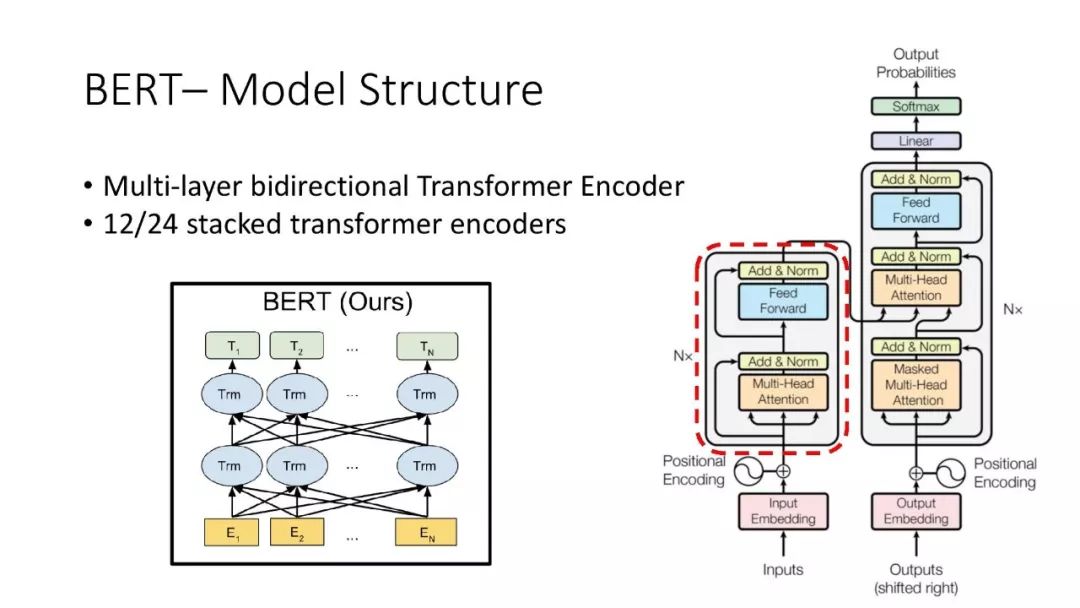
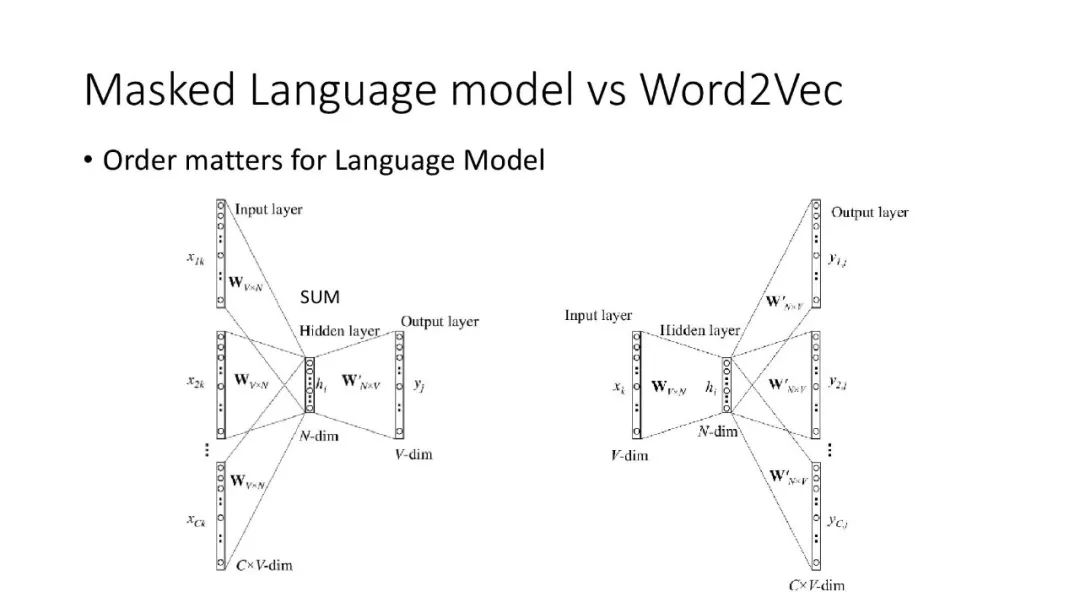




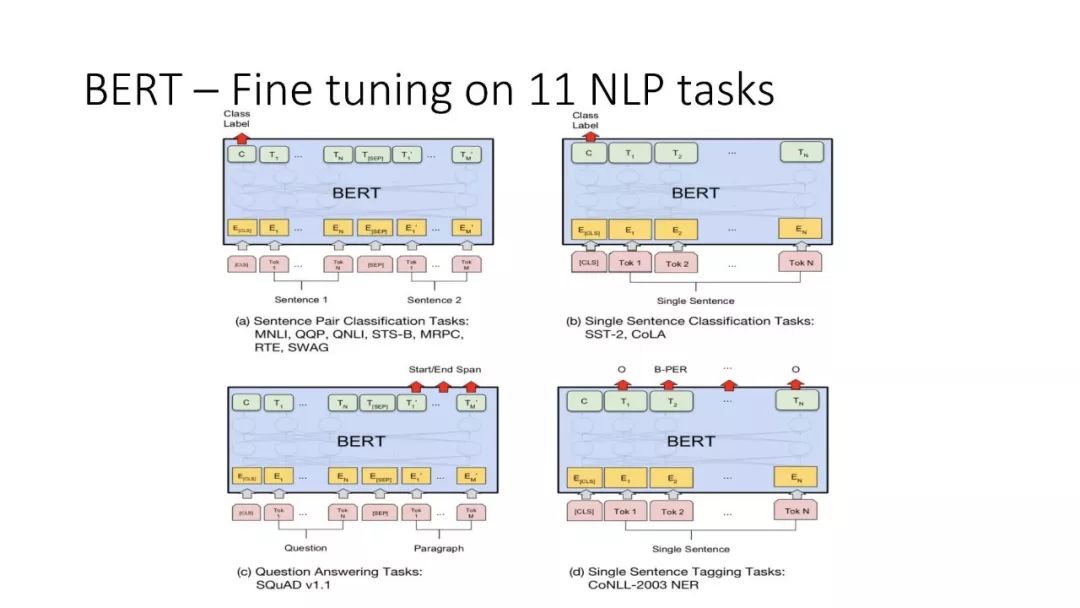


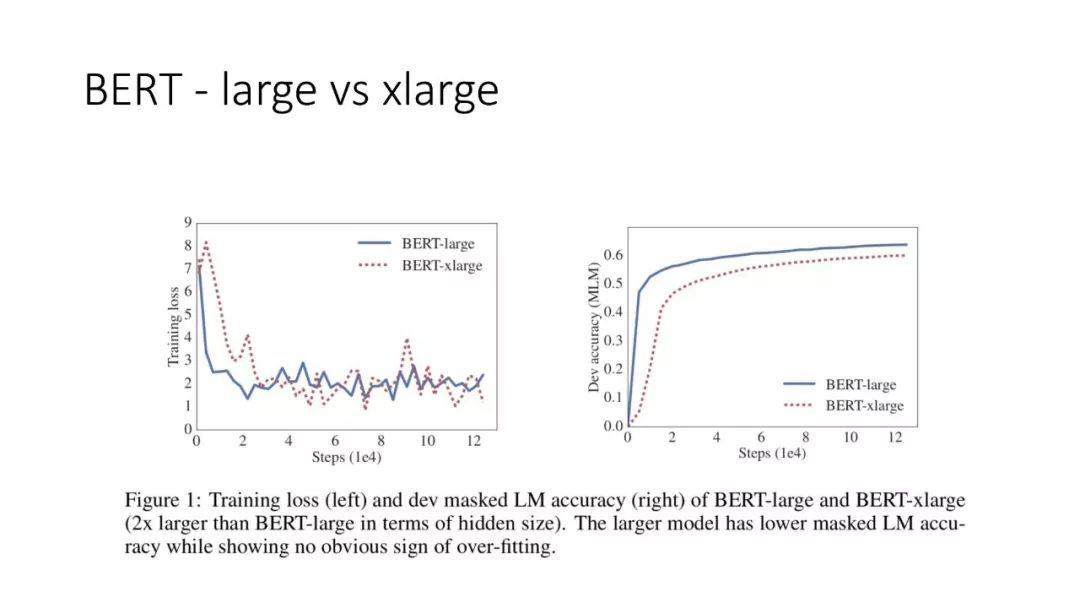
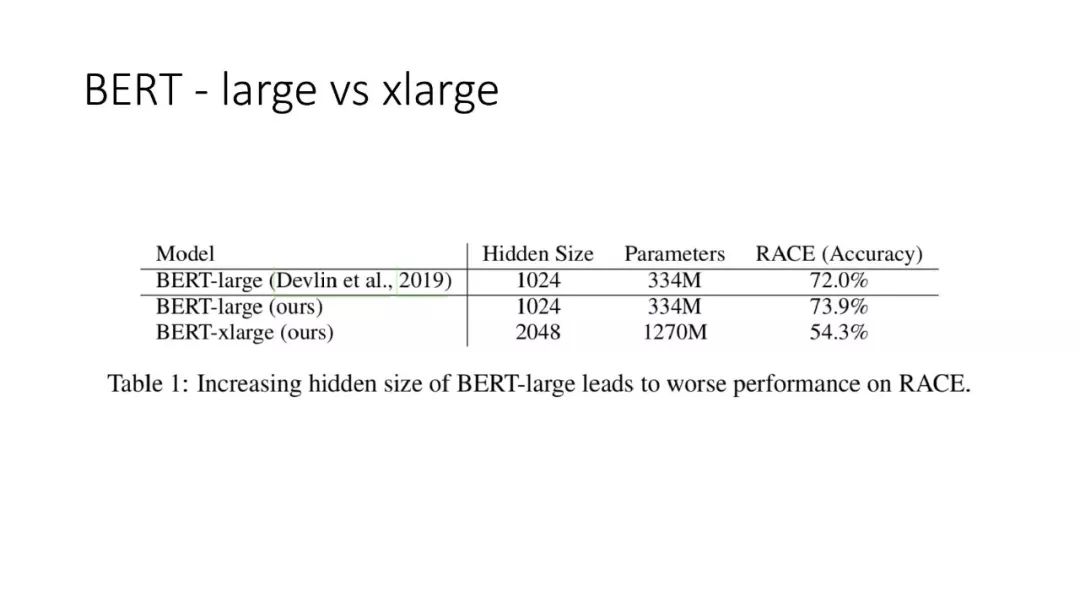




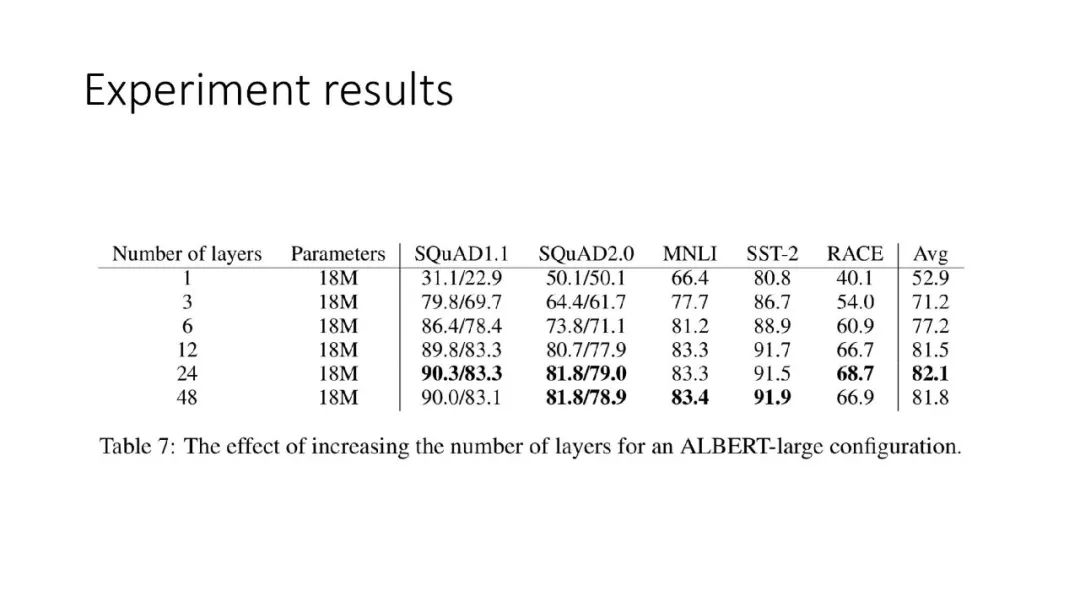
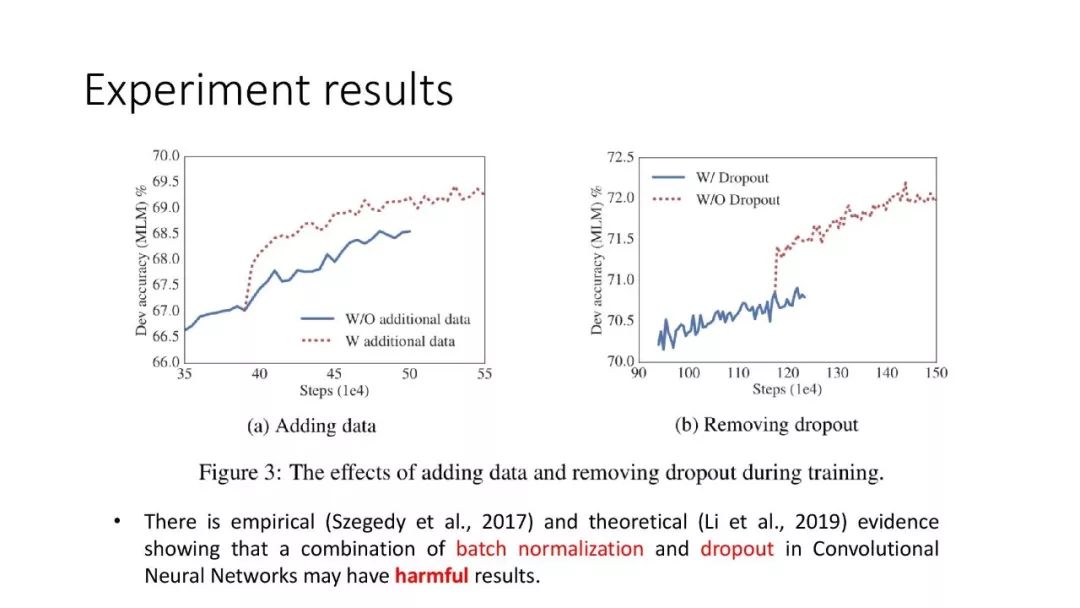
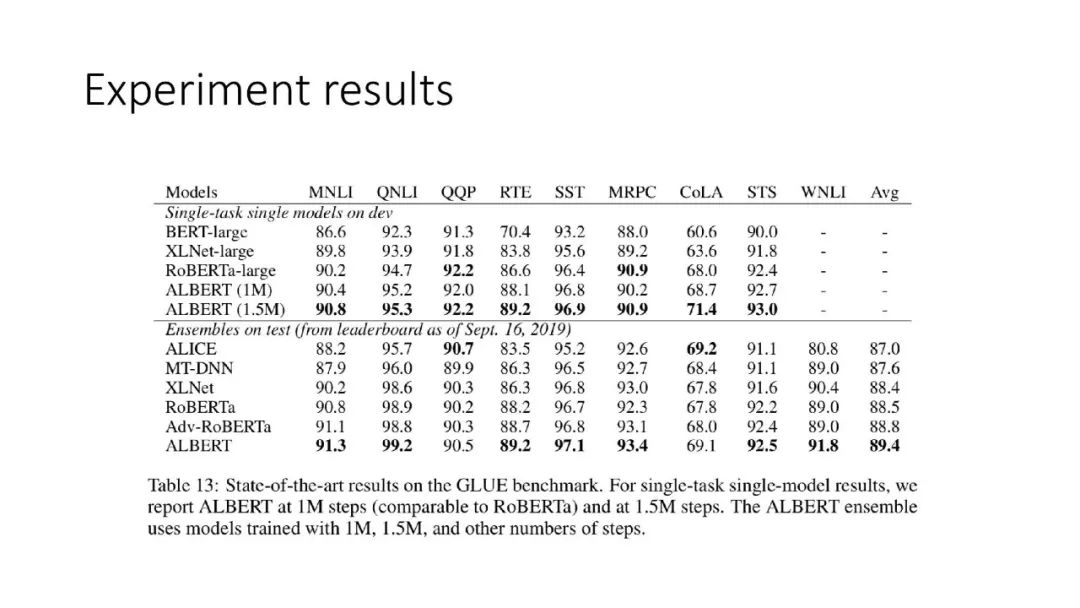
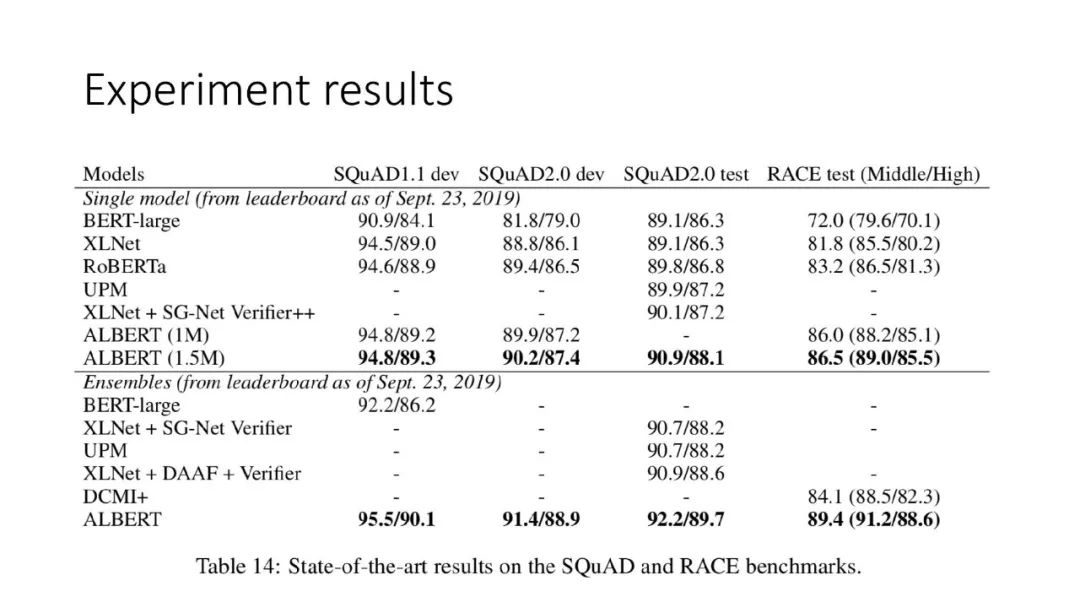

往期文章
KDD’19 | 图神经网络预测知识图谱中的节点重要性
EMNLP'18 | 利用胶囊神经网络零数据检测用户意图
深度学习模型真的无法被解释么?
Reference
[1] Vaswani, Ashish, et al. Attention is all you need. NIPS 2017.
[2] Devlin, Jacob, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
[3] Lan, Zhenzhong, et al. ALBERT: A lite BERT for self-supervised learning of language representations. ICLR 2020, under review.
[4] https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[5] http://jalammar.github.io/illustrated-transformer/
[6] https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09
[1] Vaswani, Ashish, et al. Attention is all you need. NIPS 2017.
[2] Devlin, Jacob, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
[3] Lan, Zhenzhong, et al. ALBERT: A lite BERT for self-supervised learning of language representations. ICLR 2020, under review.
[4] https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[5] http://jalammar.github.io/illustrated-transformer/
[6] https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09
[1] Vaswani, Ashish, et al. Attention is all you need. NIPS 2017.
[2] Devlin, Jacob, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
[3] Lan, Zhenzhong, et al. ALBERT: A lite BERT for self-supervised learning of language representations. ICLR 2020, under review.
[4] https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
[5] http://jalammar.github.io/illustrated-transformer/
[6] https://medium.com/@adityathiruvengadam/transformer-architecture-attention-is-all-you-need-aeccd9f50d09


