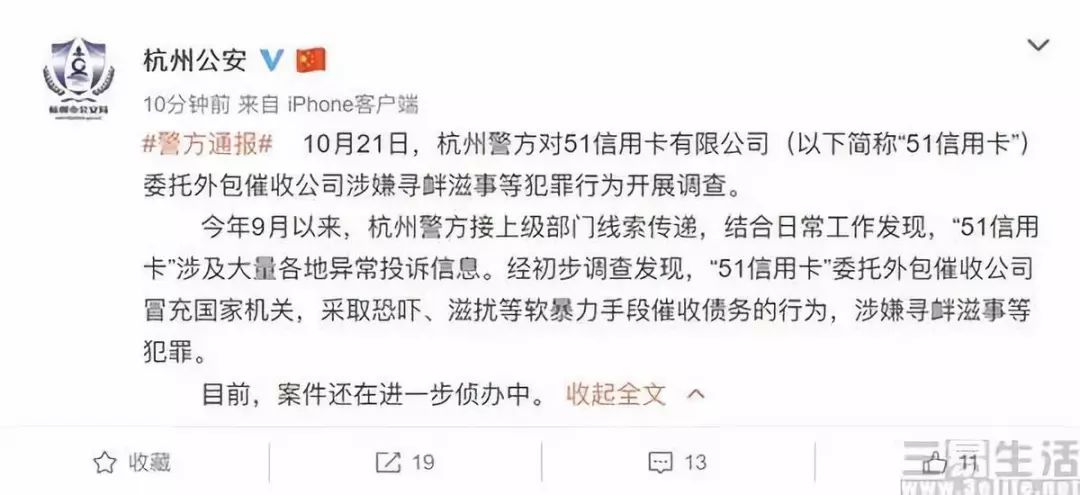
近日,以提供信用卡管理服务起家的港股上市公司51信用卡被警方调查,很快也引发了股价的瀑布式下跌,并在停盘前损失了34%的市值。由于事发突然,因此尽管一时间相关猜测层出不穷,但其中催收外包导致的暴力问题以及爬虫业务被举报,则是业界普遍认为最有可能原因。

10月21日晚间杭州警方发布通报称,“经初步调查发现,‘51信用卡’委托外包催收公司冒充国家机关,采取恐吓、滋扰等软暴力手段催收债务的行为,涉嫌寻衅滋事等犯罪”。因此也为这一事件定论,但为何此前有传言称51信用卡会因为“爬虫”翻车呢?
除了此前网络上流传的截图透露,某银行发布律师函称51信用卡方面“通过爬虫程序对我行用户信息进行抓取”之外,其所上线的大数据风控系统iCredit数据来源,也一直并未被披露其合规性。此外还有一个重要原因就是,随着互金行业获客成本的逐年攀升,相关企业通过自建爬虫体系从网络上获取用户信息早已成为业内的潜规则,而此前也曾有企业因此被警方介入调查。
对于暴力催收,想必大家或多或少都有所耳闻,无外乎是催收公司通过对欠款人进行恐吓及滋扰等非法手段。而爬虫作为一种网络技术,对于大家来说可能并不太了解,但其影响范围却更广。

所谓爬虫或者网络爬虫,是一种按照一定规则,自动的抓取互联网信息的程序或脚本。爬虫可根据一定的搜索策略从网络中选择要抓取的内容,并不断重复这一过程,直到达到系统的某一条件时停止,通俗来讲就是用程序来模拟人的操作去访问网站,然后把被访问网站上所需要的数据“复制粘贴”下来。而所有被爬虫抓取的网页则将会被程序存储,并进行一定的分析和过滤后建立索引目录,以便之后的查询和检索。
但是必须说明的是,爬虫技术为互联网行业的发展其实同样也有非常重要的意义,百度及谷歌这类通用搜索引擎就是建立在爬虫技术的基础上,进而将整个互联网更为紧密的结合在一起。并且通过爬虫技术的收集、归纳,和整理,大数据公司能够完成用户画像,技术爱好者也能以此从浩如烟海的数据中总结出有用的内容。
当然,爬虫技术之所以会广受非议,就是因为其门槛相对较低,在编写爬虫的语言中,除了有C++和C#这一类效率高但开发慢的语言之外,Python这一跨平台的可视化语言以及与之配套的教程,让只要有一定基础的人,仅需很短的时间就能编写出爬取大规模数据的爬虫程序。而技术的扩散必然就会给网络带来大量非正常操作的访问,并加重服务器负载,更况且很多网站也并非想让自己的内容被随意抓取。
因此为了规范爬虫的行为,Robots协议(网络爬虫排除标准)也就应运而生,这个协议的作用就是告诉爬虫在网站服务器上什么文件是可以被查看的,类似于“请勿打扰”或“欢迎进入”的提示。通常来说,网站自己公开的数据都是可以被爬取的,比如天眼查或企查查上的相关企业法律风险提示,就是从中国裁判文书网上所抓取,但是像起点的VIP小说章节以及知乎Live等付费内容,显然并不会乐意被爬虫随意抓取。
而最为关键的一点则是作为互联网技术的爬虫,是如何让很多大数据公司被迫关门呢?最直接的,当然是违反Robots协议或者攻击网站的反爬虫策略,毕竟公开数据大家都能抓取,那么要如何突出自身的竞争力呢?有些公司或者个人就会铤而走险,毕竟Robots协议防君子不防小人,所以通常网站都会部署自己的反爬虫策略来保护敏感信息,类似淘宝的商家信息以及交易内容等信息就是此类,因此破解反爬虫策略,也就极有可能会触犯《非法获取计算机信息系统数据罪》。

如果爬虫只收集公开数据的话,会不会有风险呢?其实答案依旧是有的。当爬虫程序访问某一网站过于频繁,导致目标网站不能正常运行时,那么其制作者就走在了违法犯罪的边缘,毕竟高频次和大流量的访问势必让网站“压力山大”,而这也已经与DDOS网络攻击行为无异了。
另外需要注意的是,即便是公开信息也有的可以收集,可有的就不行了。如今部分用户在网络上并不太注意保护自己的个人信息,有意无意间可能就会公开这些,因此一旦使用爬虫有意的规模化收集整理这些个人信息,显然就并不合法。
因此总的来说,程序员或者相关爱好者在进行爬虫时,至少需要遵循这样三个原则,即不爬取个人隐私信息、不利用爬虫非法获利,以及设定不攻击目标的反爬虫策略。而对于有意识的利用爬虫进行不当获利,其结果或许并不是大家所想看到的。
【本文图片来自网络】

推荐阅读
京东重整战投,变身下沉市场「大买家」
Android走过11年,最终却把自己变成了iOS?
支付宝小程序驶入深水区
当年两边吵到不可开交 如今每台iPad都想成为Surface
iPhone 11系列领衔 一大波苹果新品正在接近



